In class this week we looked over how
dictionaries work and have constant time, as well as doing some exam
review. Having a dictionary as a built-in data type is a fairly
uncommon feature; as seen in the lecture, the way they work is
complex. Having this ADT built in is fairly convenient for the
programmer; otherwise, they would have to code it themselves.
Dictionaries can find and insert items in constant time, meaning that
the number of elements it contains has no effect on runtime. Lists
also perform these operations in constant time, but they do not have
option to have strings (or other immutable data types) as keys. The
way a dictionary indexes its data is by hashing (giving a piece of
data a numerical value) the immutable key values (mutable key values
will not work because their hash values change if their are
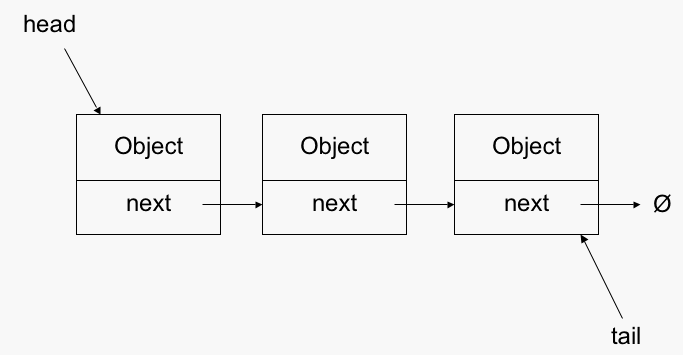
modified). If there are two different items with the same hash value,
then a linked list is used, so no matter what, finding or inserting
data will have a constant runtime value.
We reviewed all the major topics
covered in this course during the exam review: ADTs, class design and
inheritance, testing, exceptions, Python idioms, recursion, runtime
analysis, linked structures (trees and linked lists) and sorting. I
personally think that recursion is the single most important concept
in this course (which is why it has been emphasized so frequently)
because of how powerful it is. The sorting algorithms and the linked
structures we examined all utilize recursion, so it is clearly a
fundamental concept.
Overall, I enjoyed this course,
although I did find it difficult at times. I liked how we focused
more on abstract concepts than on details specific to Python (like
CSC108 did). There was nothing to memorize; critical thinking was
more important. The grading and marking schemes were pretty fair as
well. The weekly labs certainly aided me in understanding the course
material. I think I'm a better programmer (with enough knowledge to
at least learn the basics of other languages) as a result of this
course.
, I sincerely apologize.") This comic has essentially nothing to do with what I wrote above.
This comic has essentially nothing to do with what I wrote above.
(http://xkcd.com/936/)